")
To draw a line waist measure taken, it is necessary to determine the radius. To do this, simply divide the required measurements waist 3.1 (for example the rear cloth skirts 15:3,1=4.8 cm).
Draw a straight line and mark on it the length of the skirt (figure 230). From the end of the line side of the slice put a radius and draw a waist line of the rear cloth skirts (solid line).
Then, given the length of the skirt draw a line the bottom of the rear cloth (solid line).
Touches the lines of the front.
Skirt cut the "sun" of several semicircles. To get the skirt wider than a full circle, it is enough to divide the waist circumference by the number of semicircles, which requires the model and construct the drawing according to the obtained measure. For example, for the skirt of the four semicircles in the waist circumference of 64 cm 64 need to divide first into four, and then the obtained value of 3.1 (to define radius).
Skirt cut "the sun" in the Assembly. The width of a skirt at the waist greater than waist, by the amount needed for assemblies. To skirt of tulle the width of the skirt at the waist doing more waist girth by 2-4 times.
Divide the measure of circumference of waist (including allowance for Assembly) to the desired number of semi-circles and build the drawing as explained earlier.
The shape and large surface of the obtained patterns cause some difficulties cutting the skirt.
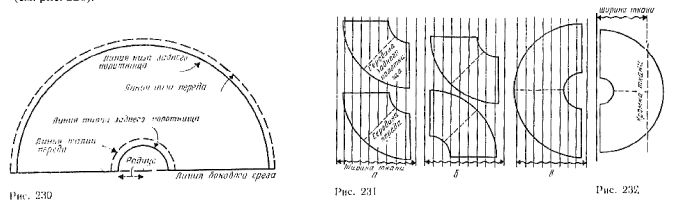
Figure 231 shows the three options for the location of parts of the patterns on the fabric in stripes.
Method of cutting the skirt pattern 231 b is the most economical. For fabrics with stripes is most appropriate cutting according to figure 231, V.
The location of the joints depends on the model. To represent the location of the stripes at the seams, and turn the strips of fabric on the pattern and connect the parts of the patterns. If the fabric is much narrower skirts, separate part of the mold which does not fit the width of the fabric (note the width of edges), and transfer it along the length of the fabric, keeping the same direction of the warp threads (figure 232).
Cut neumaticos part of the templates, leaving a margin for the seam along a straight line, and agree that part of the seam with the second part of patterns. The location of this seam is very affect the appearance of the skirt. You can make or vertical seams in the middle part (see figure 231, a, b), or extension parts (see figure 231, in).